
63-Node EKS Cluster running on a Single Instance with Firecracker
This blog post is a part of a series of posts devoted to Firecracker automation. Currently it consists of the following posts:
- Part I: Automation to run VMs based on vanilla Cloud Images on Firecracker
- Part II (current)
Elaborating on the original code created to automate the creation of Firecracker VMs, this post will show how we can create an EKS-compatible (as in Amazon’s EKS) cluster, with multiple nodes, where each node will be a Virtual Machine, all running on a single host, thanks to Firecracker.
All source code is available in this GitLab repository.
Creating an EKS Cluster out of Firecracker VMs
EKS? Isn’t that an AWS managed Kubernetes service? It certainly is, but it also is open source recently announced and contributed by Amazon Web Services. The latter form is more precisely called EKS Distro (EKS-D), and its source code is available on this Github repository.
In particular, Ubuntu’s snap-based EKS-D compatible distribution will be used, since it is
quite easy to install and operate on Ubuntu VMs. It is interesting that this distribution is based on
microk8s, and is labeled as “EKS-compatible Kubernetes”. “Compatibility” in this context
appears to be that is kind of a microk8s “dressed as” EKS, as it includes the eks binary, which works as expected
elsewhere. But because it is based on microk8s, it is probably suitable only for those cases where microk8s is.
With the code developed as part of the previous post, a configurable number of Firecracker VMs can be created
automatically, with password-less SSH configured with user fc, which can also password-less sudo. Given this, and
that we need to install and configure the instances to install Ubuntu’s EKS-D, Ansible was a
perfect candidate for this automation.
All of the Ansible code can be found in the ansible/ folder. I’m not an Ansible expert, so code is subject to many improvements (feel free to submit MRs!). Code should be quite self-explanatory –except for the inventory part, which required some additional shell scripting that can be found in the 05-install_eks_via_ansible.sh file.
There are two problems that we need to solve with the shell script:
-
Generate a dynamic inventory. Basically, the number of VMs is based on the
NUMBER_VMSvariable defined in thevariablesfile. The first node will be considered the EKS master, and all remaining nodes workers. -
After installing the
ekssnap, each node will be a separate “master”. To form a single cluster, we need to runeks add-nodecommand in the master for every node, and an equivalenteks joinin the nodes. Both commands use a token, which can be auto-generated (not convenient for this use case) or provided. The shell script generates these tokens and provide them as variables: a token for each node, and a list of all tokens to the master node.
You may run this code in your own environment. Review the
README.md
file and make sure firecracker is installed and properly configured, as described in the
first post. 4GB and 2
cores seems to be a reasonable minimum of resources needed per VM to run a successful EKS-D compatible cluster. Adjust
variables file to your environment.
Creating a 63-Node EKS Cluster on a r5d.metal instance
Wouldn’t it be cool to create a large EKS cluster, running on many VMs… all within a single “big” host? That’s the
experiment I run. I chose a r5d.metal instance (96 cores, 768 GB RAM,
3.6 TB NVMe local SSD), as the best combination of high core and RAM count and local storage (as we will be creating the
“volumes” for the VMs, and this should be as fast as possible). Then fired 100 Firecracker VMs and created an EKS
cluster…
I set the
number of Ansible forks
to 32, to have more parallelism. However, it looks like even with low parallelism there are errors with the eks join
operation caused by limits on the maximum number of requests to the kubeapi-server, so
this part of the Ansible code is serialized.
VMs configured with 2 core and 4 GB of RAM. The code worked. Scripts, ansible, all worked. A bit after 4 hours, a
100-node EKS cluster created within a single instance was running:
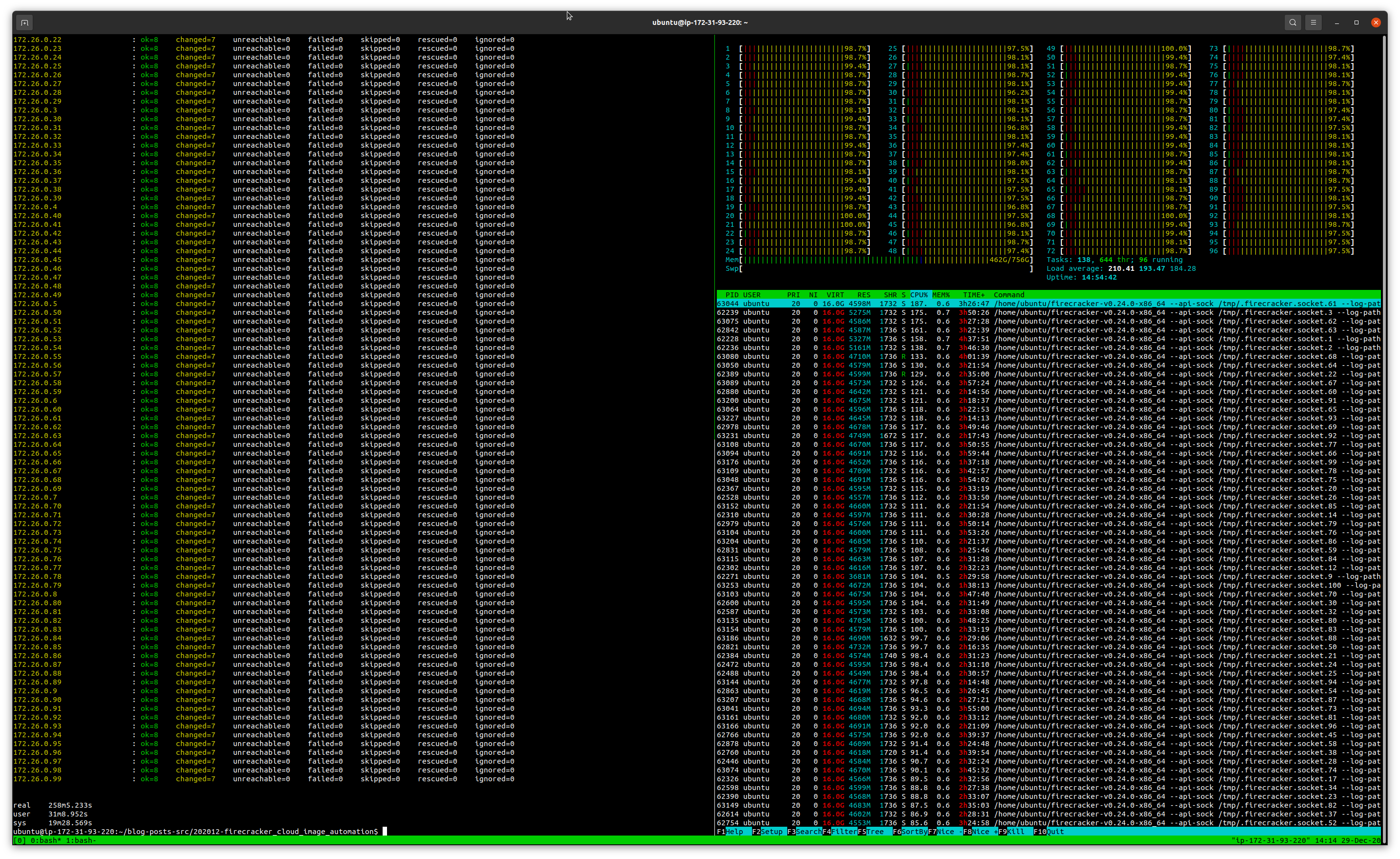
However, load was at more than 200, and while memory usage was acceptable (2/3rds of the system RAM), cluster was
unusable. But more importantly, I found an interesting fact: kubectl get nodes would only return 63 nodes, despite
the 99 node join operations were returned as successful. I didn’t dig very much, but there seems to be a limitation here
(internal microk8s limitation? Not sure anyway microk8s has been extensively tested with this high number of cluster
instances…).
So I decided to repeat the operation, but with “only” 63 VMs (after all, kubectl get nodes won’t return more…) and
bump the VM specs to 4 core (the master node VM was also loaded over 100% itself) and 16 GB of RAM (16 GB * 63 is
more than the system’s available RAM, but Firecracker allows for both memory and CPU overcommitment, as long as not all
processes use all the allocated RAM). This worked better, cluster was successfully created and kubectl get nodes
reported this time all the nodes. All in about 3h, now with an acceptable CPU load:

ubuntu@ip-172-31-93-220:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
id1394205090 Ready <none> 116m v1.18.9-eks-1-18-1
id0890521735 Ready <none> 93m v1.18.9-eks-1-18-1
id1865400204 Ready <none> 85m v1.18.9-eks-1-18-1
id3176525421 Ready <none> 79m v1.18.9-eks-1-18-1
id0289819564 Ready <none> 97m v1.18.9-eks-1-18-1
id2364814864 Ready <none> 101m v1.18.9-eks-1-18-1
id1576708969 Ready <none> 62m v1.18.9-eks-1-18-1
id0839217590 Ready <none> 95m v1.18.9-eks-1-18-1
id2385921825 Ready <none> 122m v1.18.9-eks-1-18-1
id2162009048 Ready <none> 99m v1.18.9-eks-1-18-1
id0032931251 Ready <none> 94m v1.18.9-eks-1-18-1
id1397218544 Ready <none> 83m v1.18.9-eks-1-18-1
id2509806641 Ready <none> 72m v1.18.9-eks-1-18-1
id1391026381 Ready <none> 56m v1.18.9-eks-1-18-1
id3180021860 Ready <none> 132m v1.18.9-eks-1-18-1
id2766207659 Ready <none> 130m v1.18.9-eks-1-18-1
id2417208994 Ready <none> 67m v1.18.9-eks-1-18-1
id0037315342 Ready <none> 126m v1.18.9-eks-1-18-1
id2870908982 Ready <none> 124m v1.18.9-eks-1-18-1
id0303528979 Ready <none> 96m v1.18.9-eks-1-18-1
id2443620467 Ready <none> 100m v1.18.9-eks-1-18-1
id2671116621 Ready <none> 89m v1.18.9-eks-1-18-1
id1153919941 Ready <none> 127m v1.18.9-eks-1-18-1
id1618117867 Ready <none> 114m v1.18.9-eks-1-18-1
id1345427105 Ready <none> 128m v1.18.9-eks-1-18-1
id1578112374 Ready <none> 133m v1.18.9-eks-1-18-1
id2260431270 Ready <none> 134m v1.18.9-eks-1-18-1
id1192720052 Ready <none> 131m v1.18.9-eks-1-18-1
id0009731256 Ready <none> 86m v1.18.9-eks-1-18-1
id0772428726 Ready <none> 112m v1.18.9-eks-1-18-1
id2345631371 Ready <none> 115m v1.18.9-eks-1-18-1
id0866401320 Ready <none> 90m v1.18.9-eks-1-18-1
id2295817569 Ready <none> 121m v1.18.9-eks-1-18-1
id3195221619 Ready <none> 105m v1.18.9-eks-1-18-1
id3212514411 Ready <none> 64m v1.18.9-eks-1-18-1
id2530228284 Ready <none> 58m v1.18.9-eks-1-18-1
id1582731567 Ready <none> 125m v1.18.9-eks-1-18-1
id0234531685 Ready <none> 104m v1.18.9-eks-1-18-1
id1170407709 Ready <none> 129m v1.18.9-eks-1-18-1
id2377401525 Ready <none> 129m v1.18.9-eks-1-18-1
id2782930529 Ready <none> 109m v1.18.9-eks-1-18-1
id2316206444 Ready <none> 88m v1.18.9-eks-1-18-1
id0886017938 Ready <none> 120m v1.18.9-eks-1-18-1
id2886224137 Ready <none> 135m v1.18.9-eks-1-18-1
id2137806005 Ready <none> 74m v1.18.9-eks-1-18-1
id3252717927 Ready <none> 136m v1.18.9-eks-1-18-1
id1421103858 Ready <none> 111m v1.18.9-eks-1-18-1
id2048704797 Ready <none> 102m v1.18.9-eks-1-18-1
id1892014011 Ready <none> 106m v1.18.9-eks-1-18-1
id0719403446 Ready <none> 61m v1.18.9-eks-1-18-1
id1134505657 Ready <none> 82m v1.18.9-eks-1-18-1
id0023523299 Ready <none> 118m v1.18.9-eks-1-18-1
id2477116066 Ready <none> 81m v1.18.9-eks-1-18-1
id0469627718 Ready <none> 77m v1.18.9-eks-1-18-1
id1020429150 Ready <none> 113m v1.18.9-eks-1-18-1
id1471722684 Ready <none> 91m v1.18.9-eks-1-18-1
id1417322458 Ready <none> 75m v1.18.9-eks-1-18-1
id0107720352 Ready <none> 69m v1.18.9-eks-1-18-1
id2957917156 Ready <none> 108m v1.18.9-eks-1-18-1
id0573606644 Ready <none> 3h54m v1.18.9-eks-1-18-1
id1377114631 Ready <none> 117m v1.18.9-eks-1-18-1
id0468822693 Ready <none> 119m v1.18.9-eks-1-18-1
id0660532190 Ready <none> 71m v1.18.9-eks-1-18-1
Despite all this, the cluster was not really usable. Most operations took long to complete and some errored out. Probably, the microk8s on which this EKS-D is based is not designed for this purposes ;)
Final words
The 63- and 100-Node experiment was more of a funny exercise and a validation for the scripts and Ansible code. However, the code presented is quite useful specially for testing scenarios. I can create on my laptop a 3-node EKS cluster (2 core, 4 GB of RAM per node) in under 5 minutes, all with a single-line command. And destroy it all in seconds with another one-liner. This allows for quick testing of EKS-compatible Kubernetes clusters. All thanks to Firecracker and EKS-D, both open source componentes released by AWS. Thanks!



