
jsonb supports, unsurprisingly, JSON
jsonb is, undeniably, king. It is a very flexible data type, that allows for unstructured/schema-less storage. It has very powerful indexing mechanisms, and its internal representation is reasonably compact and efficient. It comes with advanced operators and expressions to query/extract parts of it, and has recently seen the addition of SQL/JSON path functionality to extend that to comply with the SQL Standard.
There are countless posts and resources explaining the virtues of this data type and what you can accomplish with it. So nothing else to add, except to reiterate my appreciation for all those who have worked on creating and contributing to it1.
But there’s a catch. jsonb supports… just JSON! That’s great, but is it enough?
JSON data types
JSON is a container data type, which means it can store other data types contained within. And which data types it does support? From the JSON Spec, it supports the following:
- Number, which is a quite flexible “numeric” data type.
- String.
- Boolean.
- Null.
- Array, or probably better called a “bag” or “container”, a sequence of elements of, possibly, mixed types.
- Object, a collection of key-value pairs, where the value may be any other JSON data type.
jsonb maps these JSON data types, internally, to Postgres types. It is easy to see the resolved (JSON) data types:
select key, value, jsonb_typeof(value) from jsonb_each(
'{"a": 42, "b": true, "c": "hi", "d": null, "e": [42, "hi"], "f": {"a": 1}}'
);
┌─────┬────────────┬──────────────┐
│ key │ value │ jsonb_typeof │
├─────┼────────────┼──────────────┤
│ a │ 42 │ number │
│ b │ true │ boolean │
│ c │ "hi" │ string │
│ d │ null │ null │
│ e │ [42, "hi"] │ array │
│ f │ {"a": 1} │ object │
└─────┴────────────┴──────────────┘
Scalar types are mapped to boolean, text and numeric. Essentially, three different data types. Now check
all the data types available in Postgres. There are dozens. And
obviously you can extend with your own. Isn’t it a bit limiting that, in essence, you need to conflate any existing data
type to either a numeric or a text? What if you want to represent a timestamp? Convert it to text (well, Postgres
does it for
you,
but you get the point). What about a inet, or a point? What about my custom-amazing-data-type?
According to the JSON spec, this is correct and there’s nothing else to do. So the question is not about whether jsonb
has any implementation flaws, but if Postgres users are enough with “just JSON”.
I find it particularly frustrating having to store binary data (bytea) in a JSON. Since there’s no bytea data type in
JSON (nor jsonb, consequently) you need to convert it to a text representation. There are several solutions, none of
them a good enough one:
-
Convert it to a string, byte by byte. Probably a very bad option, as it suffers two main problems: one is that Postgres strings, not being strictly UTF-8 comformant (and this is a topic for another blog post…), cannot store the UTF-8 null (
\0) character. As such, if one of those bytes had the 0 value (likely), it could not be stored. Second, a sequence of bytes interpreted as a string does not have the same ordering as the original byte sequence. -
Encode in
base64. Other than the extra space, ordering is not preserved (i.e., an index on the original byte sequence would yield a different order than an index on the base64-encoded text). The solution is to use expression indexes on the decoded value, if order needs to be preserved. This adds overhead anyway. -
Encode in base32hex, an even more verbose encoding but that preserves order. There are no functions in Postgres for this encoding.
Looking beyond JSON
So how would you store other specific, more compact, or benefit from existing functions from additional datatypes, with
current JSON and jsonb? The only option to avoid data type information erasure is to encode the data type as part of
the JSON string. Something like:
{
"key1": {"type": "inet", "value": "10.0.0.0/8"},
"array": [3, {"key2": {"type": "point", "value": "(42, -42)"}]
}
It is easy to see the several drawbacks of this approach: much more verbose and storage needs; need to continuously cast; and need to do conditional casts depending on the data type.
I’m not alone in the pursue of a more generic, supporting more data type JSON-like language, like:
- MongoDB’s BSON.
- Amazon’s ION.
- Universal Binary JSON.
- DynamoDB’s Item HTTP API. This is a very interesting case, as it is a JSON-compliant input/output interface, with type definition following an approach similar to the one outlined above (where the value is an object which includes both the type and the value itself), but which is claimed to be stored internally in an optimized form (not as-is). It has interesting composite types like “homogeneus arrays”, where are elements must be of the same time or sets, which forbid duplicated values.
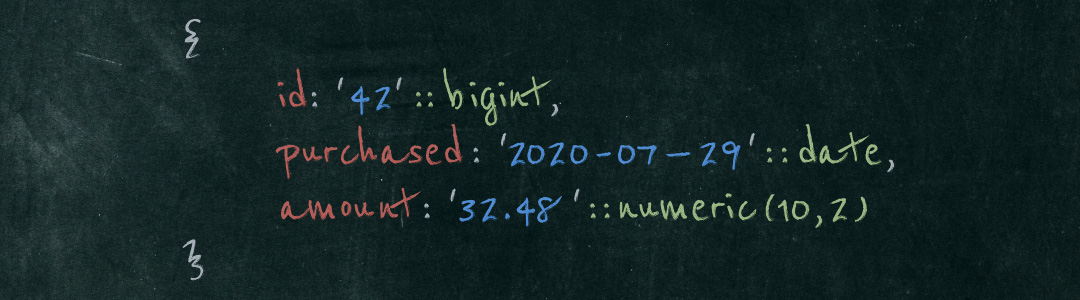
So how would such a generalized unstructured data type work in Postgres? I’d say it could leverage all the existing
jsonb infrastructure. After all, jsonb already knows each element’s data type, so this just needs to be extended to
many, potentially arbitrary data types (to support custom data types too). As such, new data types should be easy to
add. Other features (like ensuring homogeneus-ness across array elements for supporting sets; or ensuring uniqueness
within an element) may require some differentiation. Being a superset, I’d expect the same codebase could accommodate
well both data types (a similar retrofit was performed in the past from hstore to use jsonb’s codebase).
One of the main requisites is that this generalized unstructured data type would be a super set of the actual JSON, so
that any JSON string (and consequently json and jsonb values) can be converted to it implicitly. I envision the
hardest parts, or at least the ones that may trigger more discussion, to be:
- Analyze existing JSON-superset data types and deciding on the set of features to implement.
- Selecting the data types to support, if not all.
- Input syntax? Some ideas:
- Use different value enclosing depending on the data type. E.g.
key: {{ dmFsdWU= }}(Amazon Ion). - Wrap the value in constructor-like syntax, like MongoDB shell:
key: NumberLong(42). - Turn values into a nested JSON object with type (document’s key) and value, similar to DynamoDB’s HTTP API:
"key": { "N": "42" }.
- Use different value enclosing depending on the data type. E.g.
- And the hardest one: pick the name of the new datatype!
So what do you think? Should Postgres get a JSON-superset data type, a generalized unstructured data type? Leave your comments and/or tweet your responses to @ongresinc to start the conversation.
-
Personal note: I find it hard to understand why Oleg Bartunov, one of the most significant contributors to JSON in Postgres, among many other features, was recently demoted from being a “Major Contributor” to a “Contributor”. Not only I believe major contributions cannot be taken back; but in this particular case it feels even harder to understand. Let this be my public call to ask to revert this situation and provide proper public recognizement for two decades of Postgres contributions. ↩︎



