Introduction
This post is a reply to MongoDB’s “Benchmarking: Do it right or don’t do it at all” post. Which they wrote as a response to the whitepaper “Performance Benchmark: PostgreSQL / MongoDB”, published and sponsored by EnterpriseDB and performed by OnGres. While a long read at close to 50 pages, we encourage you to at least read the executive summary (2 pages) and any other relevant section, to have the right context. For a quick overview, check our presentation summarizing the benchmark and the results.
In a nutshell, MongoDB claimed that we at OnGres are PostgreSQL experts but we made “a range of basic errors in the use of MongoDB”. Then, MongoDB produced new performance results, refuting ours, without clarifying how they achieved those numbers nor publishing any source code. Ironically, they advocated in their blog response that we should have made our “benchmarks reproducible and published our results in full”.
They went on to lecture OnGres that we shouldn’t be doing benchmarks. Well, if anything, now we will definitely do more benchmarks comparing PostgreSQL and MongoDB, and continue to do so with transparency.
Our Transparent Approach
Here is what OnGres did to maintain transparency:
- We wrote a very comprehensive 50-page whitepaper explaining in great detail everything we did, why we did it and especially how we did it.
- We adhered to a strict benchmark ethics policy, which is detailed in the whitepaper (page #4) and reproduced in the benchmark presentation.
- We created a 100% automated platform to run the benchmarks, record monitoring information, and process the results. All this code is open source and can be used to reproduce our results or make changes and run your own benchmarks.
- A benchmark was written to test the ACID transactions support. It was also open sourced.
- All the raw results are public, stored on a several GB S3 bucket. Anyone can inspect them too.
We love criticism, when it’s constructive, correct and leads to a conversation that enriches database users. But unfortunately we found the tone of MongoDB’s post arrogant and unprofessional. And worse, it mixes which benchmark is which, quotes phrases out of context, ignores things that were detailed on the whitepaper and is full of mistakes. This posts analyzes and responds to the most significant mistakes, and proposes a collaborative and iterative approach to benchmarking, with transparency as key driver.
MongoDB Mistake #1: Mixing Benchmark Data
We start with the transactions test. Production MongoDB drivers have connection pooling. This makes OnGres' selection of a MongoDB driver particularly strange. They decided to use an experimental, unsupported, non-production Lua driver for the sysbench implementation they created to perform one of their three tests.
In response to the quote above, we observed that MongoDB actually began “with the transactions test” but then switched to discuss about the OLTP test. They make this mistake several times in their article. Worst of all, MongoDB kept mentioning the “experimental driver” throughout their article we used for all three benchmarks when it was used only in one: the OLTP benchmark. Its also interesting to note they also inaccurately implied that we wrote the sysbench implementation, when it was in fact developed by Percona (see page 25 of the whitepaper).
This is what we actually did:
-
Connection pooling. We test PostgreSQL with and also without connection pooling (the latter results were unrecognized by MongoDB in their response). Results for both cases were detailed in the report (pages 32, 37) and in the S3 bucket that stores all the results. The reasons we choose to use connection pooling are deeply discussed (#26-29).
-
Driver quality. Sysbench is written in Lua. Because of this, MongoDB concludes that “any reasonable tester would have looked for an alternative benchmark”. I disagree, because this means that this is the performance that Lua users get. Moreover, it tells the world how much MongoDB actually cares about Lua users, specially if this driver (which was created by MongoDB) remains unmaintained, and no other official Lua driver has been created.
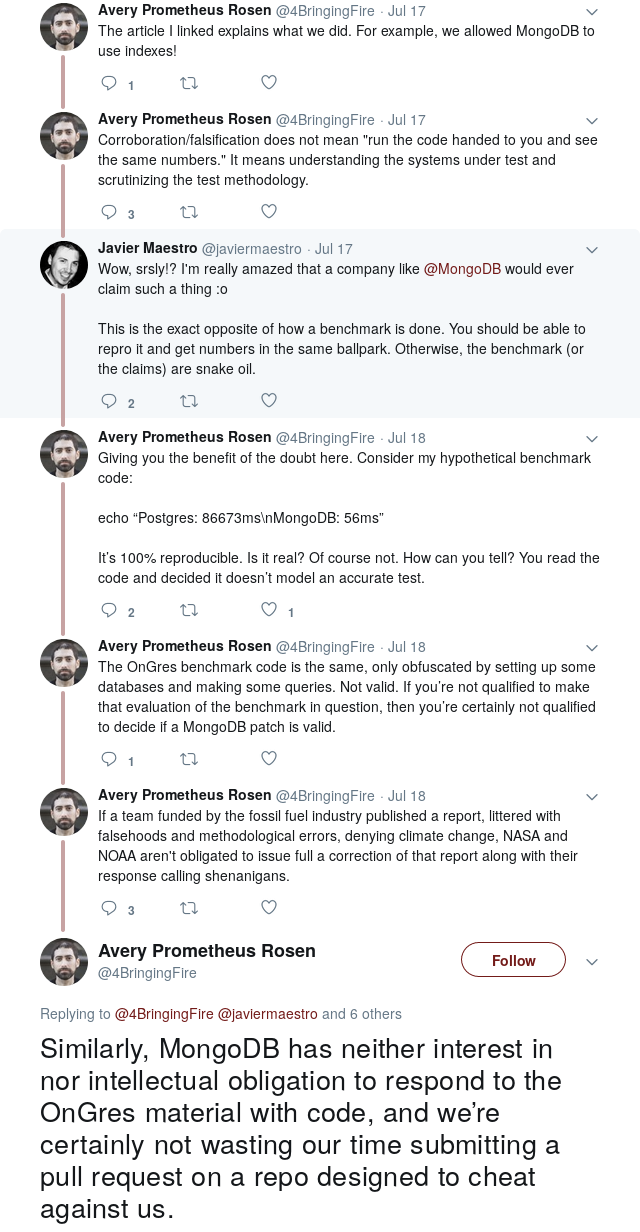
More interestingly: did MongoDB bother to patch the sysbench benchmark, update the Lua driver, add connection pooling; or replace it with another driver, run the benchmark again and publish the results? Our published source code and automation would have allowed them to do this quite easily. But no, they didn’t. Instead, as stated by their Head of Engineering Comms in a Twitter thread where several people were asking for ways to reproduce their numbers:
MongoDB Mistake #2: Misunderstanding YCSB
Sysbench was, according to OnGres, the only option for OLTP performance testing, but our experts found in their benchmark repository that they had run YCSB tests with production drivers on all sides. They did not choose to publish those results.
The claim above is completely false. YCSB was initially evaluated, but we ultimately decided not to use it. This is briefly explained in the whitepaper (#7). The main reason why YCSB was not considered is that it does not resemble a real data model (not even close!). YCSB was modeled to support (almost) any NoSQL database, and that includes even key-value databases. As such, the data model is extremely simple, contains very small records, and doesn’t resemble any reasonable data model that MongoDB or PostgreSQL users would use in real life, except for corner cases. A well-established benchmark that deals with a real data model, like sysbench, was strongly preferred.
MongoDB’s post states that “our experts found in their benchmark repository that they had run YCSB tests with production drivers on all sides.”. However, you don’t need to be an expert to find that. Anyone can just browse through the repository and find it there. That is called transparency. The fact that there’s source code to run YCSB only means that we considered and evaluated it. But we never completed full runs for all the benchmark scenarios that we contemplated on the OLTP benchmark, nor did we automate it, because it was discarded as an option. The code remains there, again, for full transparency.
Its worth mentioning that on the partial runs we did for the YCSB benchmarks, PostgreSQL was faster than MongoDB on most scenarios except for the in-memory benchmark with 4GB data set. These results were pretty similar to the ones we obtained with the sysbench benchmark.
MongoDB Mistake #3: We used the Official MongoDB Java Driver
OnGres leaned heavily on these sysbench benchmarks in their analysis for their headlines.
The post doesn’t link to it, but we assume MongoDB refers to EnterpriseDB’s press release. There, the graph and most significant headlines refer to the transaction benchmark, not the OLTP benchmark. The transaction benchmark used the official MongoDB Java driver, which uses connection pooling, and here PostgreSQL was used without PgBouncer. On this count, MongoDB has it all wrong.
MongoDB Mistake #4: Show your tuning work
For all the tests, OnGres took MongoDB off-the-shelf and compared it with their own heavily tuned PostgreSQL. They also ignored a number of MongoDB best practices […] Tuning like this is documented in our production notes, part of the MongoDB documentation. When we did, MongoDB was performing up to 240x faster.
Wow! 240x faster just by following the production notes! Can’t you include some of this magical tuning by default, so that everyday users can also benefit from this performance?
We obviously read and analyzed MongoDB’s production notes and tried to create a level playing field. But:
-
There are basically no performance configuration parameters recommended to be tuned within the lengthy production notes. There is only one mention to
storage.wiredTiger.engineConfig.cacheSizeGB, but we didn’t want to decrease the Wired Tiger cache. -
Many other recommendations were strictly followed, like binaries and versions, journaling, directories, etc.
-
Those that affect the OS (basically sysctl) were not applied. But it was not applied to PostgreSQL either.
Our benchmark was intended to resemble a reasonably optimized production platform, tuned by a “reasonable DBA”. To the best of our knowledge, most of recommended best practices in the production notes were followed. If you, MongoDB, disagree, please explicitly enumerate which reasonable best practices where omitted, with a critical performance impact, and let the world know. Or show which ones you changed in the config file to get your “exceptional” numbers.
MongoDB also claims that we compared MongoDB with our own “heavily tuned heavily tuned PostgreSQL”. If anything, at OnGres we’re obsessed with PostgreSQL tuning. We recommend best practices for expert PostgreSQL tuning, which you may read for example in our PostgreSQL Configuration for Humans talk. But when we tune a PostgreSQL system, we typically configure 30-50 parameters. For this benchmark, we only tuned 13 parameters (page #11). Of those, only 3-4 have any measurable impact on performance. And without them being tuned, PostgreSQL would be severely disadvantaged, as it ships with very conservative defaults. Tuned parameters that benefit performance:
- shared_buffers This is essentially PostgreSQL’s memory cache. By default it is 128Mb. MongoDB by default uses all system’s RAM. It must be tuned in Postgres to match.
- random_page_cost PostgreSQL by default assumes disks are rotational. However, SSDs were used. This is a parameter that is frequently tuned and easily found searching the web in e.g. StackOverflow.
- default_statistics_target = 200 May (or may not) improve the quality of the generated execution plans.
This configuration does not represent an expertly tuned PostgreSQL. Not even close. It is a basic tuning to compete on a reasonable playground with MongoDB. We can tune far better, including the OS, but we chose intentionally not to.
MongoDB Mistake #5: Dismiss Transactions Benchmark with No Strong Reasons
The OLTP benchmark was based on a teaching example for Python users written by a MongoDB developer advocate […] Ongres ported it to Java and then built benchmarking on top of that. This led to unnecessary uses of $lookup (JOIN) aggregation and other relational traits in MongoDB which are known to impact performance simply because MongoDB is not a relational database.
In response to the above claim, MongoDB yet again mixes the OLTP benchmark with the ACID transactions one.
With respect to the transactions benchmark, we took a transactions code built by MongoDB’s Director of Developer Advocacy, EMEA, and we ported it to Java. But MongoDB now considers it a “synthetic benchmark with unrealistic workloads”. How so? Actually, the intent was to resemble an even more real-world workload by including a real database of flight schedules: the application models of an airline selling tickets. Maybe this is synthetic and unrealistic workload for MongoDB, but it was a good example for this benchmark.
$lookup question
It is interesting that MongoDB critiques the use of the $lookup operation. First of all it exists and as such it may be used. Is MongoDB claiming that it is so slow that shouldn’t be used at all? If so, please update your documentation because this is not clearly advertised. Second, avoiding it comes with strings attached:
- Either you use embedding, which can lead to data duplication, inconsistency (due to non-transactional updates) and increased disk storage (and consequently decreased query performance);
- or you use references and application-level “joins”, which increase application development efforts and error-proneness.
We believed $lookup was a fair choice here. Actually, the original performance of MongoDB was one order of magnitude less than the one we published. We added some indexes in MongoDB to optimize the $lookup performance which resulted in a more than 10x win. The equivalent PostgreSQL indexes only resulted in a 2x win. Yet we published the results with both indexed versions. We definitely cared about improving MongoDB performance.
Yet, MongoDB, if you still disagree, send a merge request to the publicly available benchmark source code and re-run the benchmark with your chosen data model, and explain the potential downsides of that approach.
MongoDB Mistake #6: You can’t tune benchmark queries
With the addition of a simple hint to direct the query to use the indexes, the MongoDB queries were a magnitude faster than PostgreSQL. MongoDB also recommends the use of compound indexes, something PostgreSQL documentation argues against. For MongoDB, the addition of some compound indexes got one query to run 98% faster than PostgreSQL […] The field being queried in Query D didn’t exist in the database records. When we added a compound index for that field, both MongoDB and PostgreSQL could answer instantly with “there’s nothing here to search”.
What MongoDB describes above is called “gaming the benchmark”. You cannot tune specific queries!
The idea behind the OLAP benchmark is that you respond to analytical queries launched by Business Intelligence tools. You cannot predict which queries they will run, or how they will be run. Thus, you cannot tune for every query. Nor you can create dozens of indexes in the hope that some will be picked. Because these indexes may harm the OLTP write performance.
If anything, DB Benchmarking 101 is that you cannot tune your system specifically for the expected queries.
Worse, MongoDB did not publish what indexes they created, on what servers did they run the tests, nor what configuration or tuning they used for MongoDB. That’s why their results are just unicorns until someone can reproduce them.
We were, indeed, surprised with PostgreSQL’s performance. We did not expect PostgreSQL to fare this well on a JSON native benchmark. More importantly, as PostgreSQL experts we could have definitely tuned PostgreSQL very heavily (but didn’t) and get orders of magnitude better performance. For example, we could have:
- Used jsonb path lookup instead of chaining operations, which is faster.
- Exploited PostgreSQL’s parallel query.
- Used PostgreSQL 11’s new JIT facility to compile on-the-fly SQL queries to native code, significantly improving the execution time for OLAP-style queries.
- Used partitioning, that could have optimized significantly query execution, specially coupled with parallel query.
- Used immutable, compressed columnar storage for PostgreSQL (cstore_fdw), which is a good fit for events data.
- Used the TimescaleDB extension.
And last, but not least, we could have applied a transformation of the JSON data into a relational schema. If we would have done that, we may have achieved results up to 267 times faster than MongoDB, as the ToroDB project already proved before.
TPC-C
MongoDB considers that TPC-C is a more realistic transactional workload than the one we did. We would certainly love to compare PostgreSQL and MongoDB on TPC-C! But honestly, why implement a benchmark that was standardized 17 years before the very first version of MongoDB was released? Why not work on adapting TPC-E or even TPC-H? They are much more modern and complete.
In any case, I’m also going to VLDB and I had already planned to attend Asya’s talk. I would be happy to have our teams discuss more about MongoDB and PostgreSQL benchmarking at VLDB.
Last words
All in all, we found MongoDB’s response and discussion on Twitter incredibly shocking. Anyone –and more so a publicly traded company– should adhere to higher professional standards. Demeaning others or accusing them of creating benchmarks “designed to cheat you” has no place in a professional tech note –or anywhere else, for that matter.
We don’t claim that our benchmark is perfect. We’re open to stand corrected, receiving merge request from MongoDB to improve querying, indexing and configuration. Or new benchmarks. And take the discussion from there. All of our software is public and open source. Follow this spirit and join us on this benchmarking journey!
At the very least, exercise transparency. Transparency is paramount in benchmarks and claims about performance. Without transparency, no third-party can reproduce MongoDB results –and thus, benchmarks are meaningless. We sincerely hope that MongoDB follows-up with an objective, clear response including the full benchmark methodology, source code and means to reproduce it. Just like we did.



