Free 1GB Postgres Database on AWS CloudShell
TL;DR
AWS CloudShell is a CLI embedded in the AWS Web Console. It is meant to make it easier to run the AWS CLI, SDK and other scripts from your web browser, without having to install anything locally or having to deal with local credential and profiles management. It is a free service.
It is interesting that you can persist data on your $HOME (up to 1GB!). And this presented an obvious opportunity to
run our favorite database, Postgres, on this environment. Because we all know that
everything is a database. AWS CloudShell, too.
If you want to claim your free 1GB Postgres database, per AWS account, per region, you just need to run the following commands and wait a few seconds/minutes:
curl -s https://ongres.com/install_postgres_aws_cloudshell.bash | bash
source .bashrc
psql
(yes, yes, it is a bad practice to run shell scripts from the Internet; please go ahead and
inspect the short source code
before running it; validate that its sha256sum is 102eae7190ba7a4d148d44a62f29c10cfe9d77ffa34eb66438ce5e06941bf6c4;
you get the point)
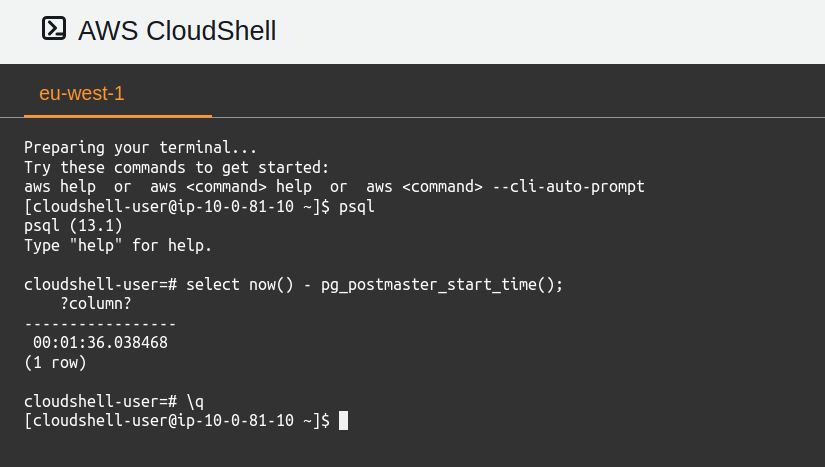
What???
Yes, you read it well. You can run, for free, a Postgres database on AWS CloudShell, with 1GB (almost) of storage. One instance per region (where CloudShell is available) per AWS account. There are a few caveats, derived from the environment, but this is an otherwise unrestricted, non-managed Postgres database:
-
The instance is not permanently running. Only when you enter the CloudShell from your web browser. Buy hey, this is almost like Aurora Serverless! (well, almost…)
-
You can’t possibly connect to it from the outside. Only locally, and it is configured with this assumption in mind. But still, you can even use it as your Terraform state storage!
-
There are no replicas (no failover) nor backups. Thought both could be added…
How it works
The CloudShell environment is a bit restricted, so you cannot just yum install postgresql. In particular, only your
$HOME folder is persistent. This means that no packages can be installed from yum (they may be wiped out).
Postgres will be installed in your home directory: both binaries –in postgres-13 folder– and data –in pgdata
folder–. We can neither assume the presence of any external library that Postgres may call/link to, as those would
also not exist if installed via the package manager –we could install them into our $HOME too, but that seemed excessive.
The script needs to be run only once, for the installation. It downloads Postgres source code, configure it with some
appropriate options to keep everything local and not require any additional shared libraries not present in the base
image, compile and installs it locally. Note that some packages are installed via yum (and those will be lost) but are
only needed for compilation, not for running Postgres.
Then the Postgres binaries (including the command line client, psql) and the command to start the database are added
to your .bashrc. So anytime you open CloudShell, your database will be available already for you. Just type psql.
However, what happens when the CloudShell is passivated? Postgres is then abruptly killed. Good news is that Postgres is a durable database, and is designed to survive to these situations. Upon restart, Postgres will find that it wasn’t shutdown cleanly, and will start recovery. Unless you were doing heavy write load, this recovery process will be quite fast. If you check the logs, they will be similar to:
2020-12-17 08:45:32.894 GMT [59] LOG: starting PostgreSQL 13.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180712 (Red Hat 7.3.1-11), 64-bit
2020-12-17 08:45:32.894 GMT [59] LOG: listening on IPv4 address "127.0.0.1", port 5432
2020-12-17 08:45:32.905 GMT [59] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2020-12-17 08:45:32.915 GMT [61] LOG: database system was interrupted; last known up at 2020-12-17 01:26:37 GMT
2020-12-17 08:45:33.001 GMT [61] LOG: database system was not properly shut down; automatic recovery in progress
2020-12-17 08:45:33.006 GMT [61] LOG: invalid record length at 0/17AB4B0: wanted 24, got 0
2020-12-17 08:45:33.006 GMT [61] LOG: redo is not required
2020-12-17 08:45:33.037 GMT [59] LOG: database system is ready to accept connections
Also, a slightly optimized configuration for this environment is installed by the script. The most notable tuned parameters are:
-
max_connections There are two cores on CloudShell, and they appear to be heavily throttled. Plus we’re not serving really network traffic. Better to keep the value low. Also the configuration includes limiting the processes parallelism, taking into account the only two cores available.
-
Storage. If you do bulk loadings, you may end up generating a fair amount of WAL, that decreases the effective storage you may have for your data. So min_wal_size has been set to its minimum possible value in this scenario and max_wal_size just to 64MB (4 wile segments) to leave some room. If you want to maximize your data storage space you may have both parameters set to 32MB.
-
Memory parameters. There are 4GB of RAM (nice!), so we can bump up a little bit shared_buffers, work_mem, maintenance_work_mem and effective_cache_size.
-
Crash recovery. This is very important, since our favorite database will be shutdown abruptly many times. The first measure is to make frequent checkpoints (by reducing checkpoint_timeout to the minimum value) while increasing the activity of the background writer, and disabling the “frequent checkpoint warning” –checkpoints they will now be intentionally frequent.
-
No replicas. Finally we restrict some parameters and minimize wal production knowing that (at least for this post’s shake) there will be no replicas.
The complete configuration applied to Postgres on CloudShell is the following:
Next steps
This could be taken further. It could be possible to add WAL-g and make continuous database backups to S3. Then, by using S3 Cross-Region Replication, that backups and WAL files could be transferred to another region. And then restore them on another Postgres running on CloudShell and have a read-only replica.
Imagination is the only limit. What’s next, what’s your take?



