
A comparative approach between Generated Columns and Triggers
In this post, we are going to describe how Generated Columns work and how much it improves query execution times, compared to trigger-based solutions.
For the test set, we analyzed the performance of INSERT and UPDATE operations using Generated Columns against C and PL/pgSQL based function triggers.
This blog post includes a ready-to-go laboratory with the full battery of tests at this repository. We encourage you to follow the instructions from Annex I to test them on your own machine!
Generate Columns feature introduction
PostgreSQL 12 includes a new feature called Generated columns which consists of columns whose values are derived or depend on other columns from the same table, as long as these are not generated columns too. It has other restrictions such as the inability to use them as part of a Primary Key composition or as part of a Partition Key. More details can be found on the official documentation. This feature brings direct benefits for INSERT operations, significantly lowering the execution times, when compared with standard PL/pgsql trigger implementations. It is worth noting that as of now it still doesn’t have a full set of Virtual Column capabilities, as it stores (rather than compute on-the-fly) the value.
The syntax to define this kind of column is the following:
CREATE TABLE my_table (
r int,
area numeric GENERATED ALWAYS AS (r^2 * pi()) STORED );
wher they keyword STORED is required; and r^2 * pi() is the expression to be computed.
Even though this feature seems a remembrance of an deterministic (IMMUTABLE as in PostgreSQL) implementation of trigger function, it comes with less performance penalty and leaner backend-side data structure coding. Prior to version 12, this feature can be emulated using immutable functions for triggers, but that requires extra coding and support. Generated Columns only support IMMUTABLE functional expressions, which makes the custom trigger approach an option whenever complex business logic or non deterministic data is manipulated.
Tests and Results
The following setup was used for the benchmarks:
- EC2
m5a.xlargein AWS (4 cores, 16 GB RAM) - Ubuntu 18.04.4 LTS (Bionic Beaver)
- Provisioned IOPS SSD (io1) 1000 IOPS
- PostgreSQL 12.3 with the following configuration:
- shared_buffers = 256MB
- work_mem = 4MB
- max_wal_size = 5GB
- checkpoint_timeout = 30min
- autovacuum = off
For this post, we’ve also built an extension called trigger_test (Annex II), which contains all the necessary structures, functions and their corresponding triggers. The trigger_test extension uses the pg_stat_statements extension to log the INSERT/UPDATE operations times. The table’s structures are simple, they have a column to store the value of the square’s side, and a second column to store the area of the square and a timestamp based column – used for update operations–. The area column is the “generated” column that depends on the first (i), like the example shown above.
This extension includes the following tests, stored in different tables as shown below:
| Table Name | Description |
|---|---|
| tab_gc | Table with Generated Column |
| tab_trg_c | Table with C trigger |
| tab_trg_c_im | Table with C trigger and immutable definition |
| tab_trg_plpgsql | Table with PL/pgSQL trigger |
| tab_trg_plpgsql_im | Table with PL/pgSQL trigger and immutable definition |
INSERT Operation benchmarks
These numbers were averaged after 3 running cycles of pgbench which include 510 INSERT calls for each custom script and corresponding destination table; pgbench parameters for INSERT can be seen in Annex II.
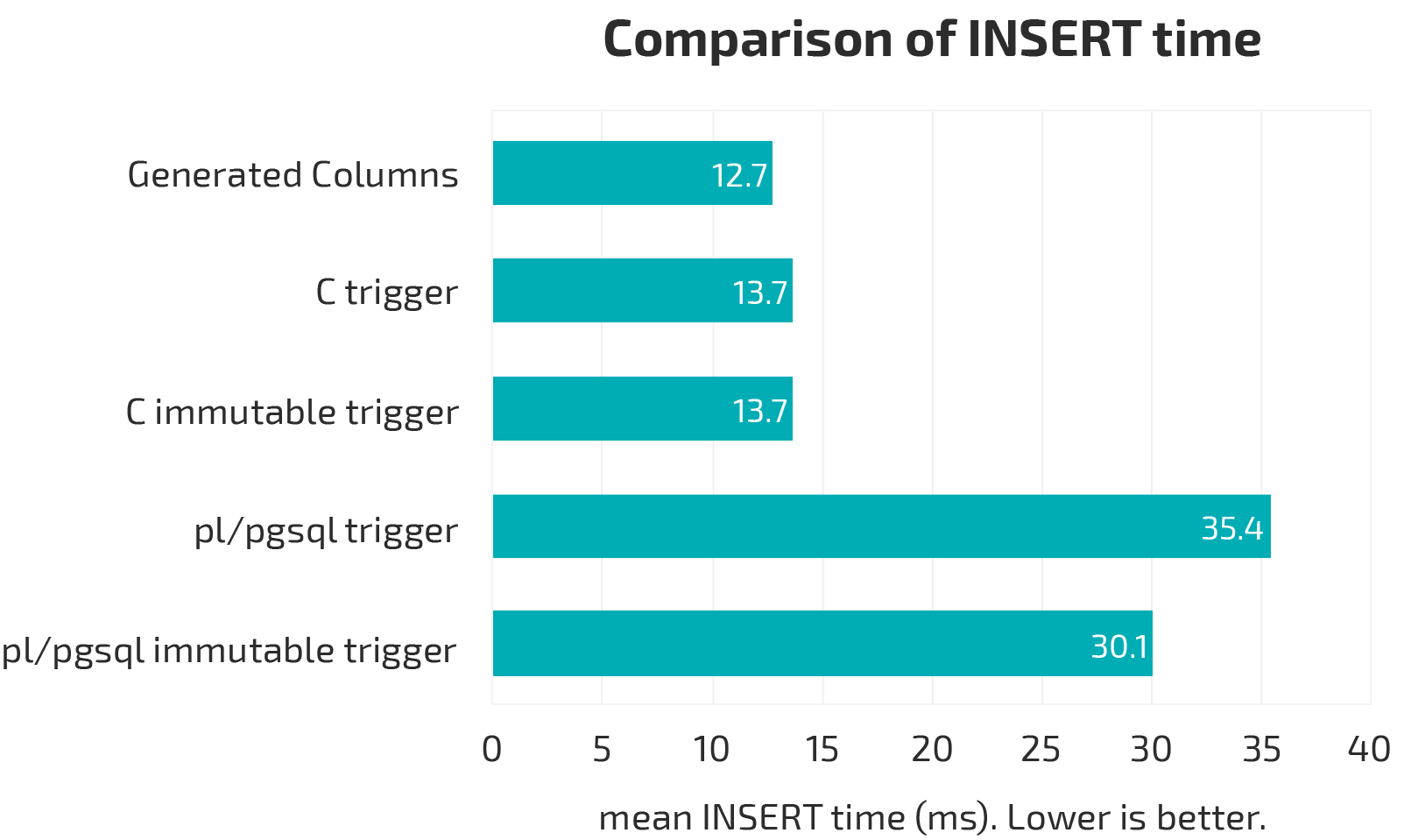
As shown in the above graph, a visible enhancement is appreciated in favor of Generated Columns over all the other mechanisms. It can outperform standard PL/pgsql immutable triggers in a scale of 0.5x and a slightly better performance compared with C based triggers.
UPDATE Operation benchmarks
In the case of the UPDATE operation, the numbers shown were produced by 3 pgbench load cycles and 30 calls per each custom script. The pgbench parameters for UPDATE can also be seen in the Annex II.

For UPDATEs, it is expected to see less impact in the overall execution, although a slightly better performance towards generated columns going up to 3% compared with PL/pgsql triggers.
Conclusions
The response times for INSERT operations in the table with Generated Column show significantly better performance than the other tables with triggers, even slightly better than triggers written and compiled in C. UPDATEs show similar or slightly better response times. This confirms that the Generated Columns feature offers better performance for INSERT and UPDATE operations, with the additional benefit of a leaner syntax.
Once more, PostgreSQL continues evolving with new exiting features such as this one, on top of which we expect more enhacements and news.
Annex I
To keep the tests reprodicibility straightforward, we’ve built a docker-compose laboratory, which includes the trigger_test extension described in Annex II. This laboratory can be reproduced doing the following steps:
curl https://gitlab.com/ongresinc/blog-posts-src/-/archive/generate_column_vs_trigger/blog-posts-src-generate_column_vs_trigger.tar.gz\?path\=202005-generate_column_vs_trigger --output blog.tar.gz
tar xzf blog.tar.gz
cd blog-posts-src-generate_column_vs_trigger-202005-generate_column_vs_trigger
Once you are placed inside the uncompressed directory, you can proceed to reproduce the steps by issuing the following scripts in order. More information can be found at the README.md:
./clean.sh
./init.sh
./test.sh
./render.sh
Annex II (trigger_test custom extension)
The current post uses a custom extension that you can build on any Postgres instance that has the devel headers, make and gcc. This extension can be found and downloaded at our docker-compose laboratory, under trigger_test folder.
For compiling, it is required a few dependencies and compilation tools. enter the trigger_test directory and run:
sudo apt-get install -y make gcc postgresql-server-dev-12
cd trigger_test
make
make install
Add the following PostgreSQL configuration to your testing instance:
autovacuum='off'
shared_preload_libraries='pg_stat_statements'
shared_buffers='256MB'
max_wal_size='5GB'
checkpoint_timeout='30 min'
Then, proceed as usual for installing the extension inside the database:
CREATE EXTENSION trigger_test CASCADE;
Inside the extension folder, data can be loaded using insert_data.sql and update_data.sql files in this order.
#using load files with pgbench
pgbench -U postgres -n -T 60 -c 1 -f insert_data.sql databasename
pgbench -U postgres -n -T 60 -c 1 -f update_data.sql databasename




