
There is an ongoing and engaging open discussion in the Postgres Community around the future of Postgres extensions. At OnGres we have been operating for around three years a Postgres distribution and repository with around 200 extensions for StackGres, a fully-featured open source platform for self-hosting Postgres on Kubernetes.
We would like to contribute to the discussion with all that we have learnt through this experience. We would also like to explain what we believe is the future of packaging and distribution of Postgres extensions.
Extensions in StackGres
Wide support for Postgres extensions was introduced in StackGres in our first GA release, 1.0.0, in 2021, with over 120 extensions supported at the time. This release included a new technology to dynamically load and unload extensions from the filesystem. It allows to create minimal Postgres images (avoiding the bloat and security risk of including dozens or hundreds of extensions in the image, most of which will remain unused) while allowing a fantastic user experience: to specify anytime, via YAML (or via StackGres Web Console), which extensions you want to have available in Postgres.
spec:
# [..]
postgres:
extensions:
- name: postgis
- name: timescaledb
version: "2.13.0"
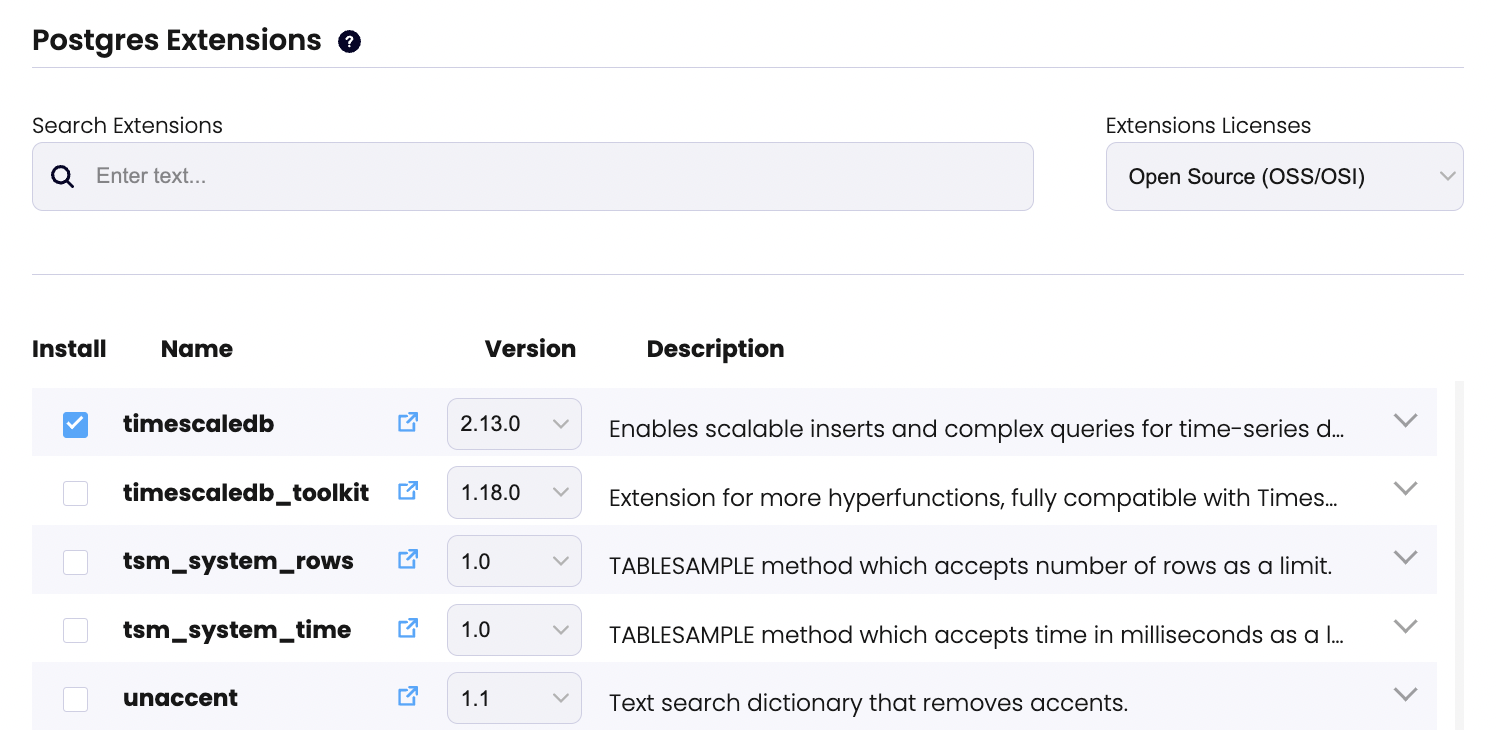
The example shows the YAML snippet required to add Postgis (latest version) and Timescaledb (version pinned to 2.13.0) in StackGres (above); and how to browse, select and add extensions to StackGres via the Web Console (below).
If you are interested in the internals of this technology, which is fully open source (as part of StackGres), I gave a talk at Kubecon North America 2021 about it (video, slides).
As of today, StackGres supports close to 200 extensions, and more extensions are being added on a rolling basis. In parallel, we’re hard at work on a new infrastructure to build better, faster and more Postgres extensions (more about this in this post).
StackGres’s extension repository is currently serving 1.5M extensions per month, which amounts to 1TB of data. Over the last two previous months, the most popular extensions served were Citus (with Citus columnar), Timescale, dblink (it’s used internally by StackGres on some setups), postgres_fdw and adminpack. All extensions are offered both in AMD64 and ARM64 architectures (except where they don’t compile).
(Citus has become extremely popular in StackGres thanks to the integration to create Citus Sharded Clusters).
Postgres and its extensions are to be married together
Postgres extensions (or at least those that are in compiled format and loaded into Postgres memory, which are the wide majority of the extensions) present an inherent risk to the database. They are usually less trusted pieces of code, fetched from Git repositories, that may potentially crash, corrupt or delete your data. That doesn’t mean they shouldn’t be used, and usually most extensions work perfectly well and are completely harmless. But there’s a security risk assessment that needs to be done about them, and this is the main reason why only a limited selection of extensions is present at most Postgres DBaaS, as they need to be explicitly vetted.
Key to keeping these risks controlled is to not introduce additional risks via the way extensions are built. In particular, extensions should be built with the same “host OS”, libc and even the same compiler and compiler version that are used to build the Postgres server where they will be loaded.
In particular, Postgres is quite sensitive to the libc version being used, and mismatches may lead to silent data corruption. Same happens with ICU, even though its (explicit) use (in extensions) is much less common. Different OSes may have different versions of libc and other dependent libraries, and to the extent of my knowledge it is not guaranteed to be completely safe to load dynamically code compiled with different compiler or compiler versions into a Postgres database.
Therefore, to avoid introducing additional risks, both Postgres server and extensions should be compiled under the very same environment. This means that, in essence, the problem of packaging and distributing Postgres (binary) extensions is in reality a problem of creating a Postgres distribution with Postgres extensions. They are to be married together.
What’s an OCI image
The OCI Image Specification is an Open Containers standard. It’s easy to read and follow. The TL;DR is that an OCI image is a set of layers with some metadata attached to them. These layers are anything that you want (code, binaries, files, configuration) packaged on a tar file called “blob” (that can be compressed with Gzip or Zstd).
OCI images are layered (having zero or more blobs), and each layer could be reused independently (and cached by clients locally, proxies, etc). Layers are ordered, and can add, remove or replace existing files from any layer underneath. But they are otherwise independent of each other.
The OCI Image itself it’s just a manifest (or an index to manifests) and a reference to its composing layers. Every layer and the manifest itself (and indexes if any) are considered to be immutable once built and referenced uniquely by a digest (typically a SHA-256).
OCI images support “multi-arch images”, which are no more than an index metadata that points to a manifest per architecture, making it easy to have the same image built for multiple architectures. Clients using those images only pull the index and then the appropriate blogs for their architecture.
OCI images support adding metadata about the images, as labels (arbitrary key-value pairs). This is a standardized way to provide image metadata, including author, source repository, license and many other fields. An image creator may add any number of labels with any keys and values. I plan to do a follow-up post on the use of labels in OCI images to represent the various pieces of metadata information required for both Postgres and extension images.
Why Postgres Extensions should be packaged and distributed as OCI images
It’s all about not reinventing the wheel, and leveraging the ecosystem around OCI. Many of the problems (solutions) in building, packaging and distributing extensions are already solved by OCI: there’s a whole ecosystem of tools around OCI that provide additional benefits in terms of tooling, infrastructure and common knowledge.
In particular, OCI and its ecosystem provide significant help in:
-
Building. There are countless tools to build OCI images: Dockerfile, Earthly, Dagger, Bazel, Apko, Buildkit (low level or via custom front-ends) and even Nix. In general, these tools are very well known (e.g. Dockerfile) and usually easy to use. They include capabilities to compile source code, perform testing, and to add metadata. Some (most) of them also support advanced caching mechanisms, so that compilation and packaging stages can be reused if those parts of the images are not modified. There is also a large number of hosted and SaaS services to create build infrastructures that can scale to any size and complexity.
-
Packaging. The OCI image format is a very convenient format for packaging extensions, and it’s not too different from other usual package formats. Even if a new format would be purposely defined to package Postgres extensions, it would very likely be similar to an OCI image. After all, an OCI image is, at its core, a set of layers which are usually tar.gz (or tar.zstd) files with some metadata attached to them.
A notable advantage is that the layered nature of OCI images enables patterns where some layers are kept unmodified and some layers are rebuilt when new versions appear. For example, given an extension which needs to include transitive libraries as dependencies, if a new version is developed but the transitive dependencies are not upgraded, the layer that contains those libraries needs not to be rebuilt (and therefore remains cached everywhere) while only the new layer with the new version of the extension is built and used to construct the new image.
There are also multiple tools to introspect an OCI image (e.g. Skopeo), which allows inspecting the layers, contents, digests and metadata by simply pointing to an image URL.
-
Distribution. OCI images are served (distributed) by OCI registries (for technical details see OCI Distribution Spec; TL;DR: it’s an HTTP API). There are extremely popular OCI registries (like Dockerhub) and a wide variety of open source registries, like the CNCF Distribution Registry (former Docker Registry) or Harbor. They provide all the required capabilities to operate the distribution of OCI images at any scale. Moreover, there’s enough knowledge and infrastructure in the industry to support accessing, proxying and caching OCI images. OCI images can be cached extremely well by CDNs, and it’s trivial to move images to other registries and to create complete mirrors and proxies. The OCI registries also have open and well-known APIs for querying information about the images stored.
Using the OCI format and an OCI registry for serving images would solve a large class of problems (operating an artifacts repository including securing and scaling it, user authentication, providing multi-tenancy, statistics, and many others) that are often a late thought when defining a new packaging and distribution format.
-
Security. There are several additional standards, tools and systems that enhance the OCI ecosystem, in particular (but not exclusively) in areas like security. There are image security scanning tools, like Trivy, Clair or Falco. These tools scan an OCI image for security vulnerabilities and generate human and machine readable reports. They can even integrate with OCI registries to perform image scanning just by pushing an image to them.
There’s OCI image signing, which provides a way to authenticate the origin of an image with digital signatures. In OCI there is support for attestations: companion information about an OCI image that can detail parts of the build process and components, and help to prevent supply chain attacks. Attestations may include SBOMs (Software Bill of Materials; a detailed, machine-oriented documentation about the components of which a given software is built with), SLSA Provenance (“the verifiable information about software artifacts describing where, when and how something was produced”), build logs and other artifacts.
Sure, we can build all of this by ourselves. We can define a new packaging format for Postgres extensions; a metadata format for extensions; a way to digitally sign packages for Postgres extensions; a way to host them on an HTTP server and create some JSON indexes of the packages; a way to support installation on air-gapped systems; a way to generate SBOMs; tools to introspect the contents of the defined packaging format; we can implement APIs to integrate with security analysis tools or create our own; we can create our own APIs to expose the metainformation about the packages contained within a repository. But then, we would spend huge efforts in doing all this while we will not be focusing on our “business logic”, which is to build and package Postgres and its extensions, and do it well.
Let’s not reinvent the wheel: let’s leverage OCI.
But I don’t want to run Postgres on containers!
This is a bit off-topic, but let me say it anyway: I strongly believe that by default you should run Postgres on containers, including Kubernetes. If you disagree with me, or you are piqued by the interest, see my slides about the topic and/or join me at the Postgres SV Conference where I’ll give a talk about it.
Note that throughout this blog post I haven’t talked about containers, but just OCI images. Sure, they are often loosely referred to as “container images” or even “Docker images”. And while they are designed and arguably most of the time used to run containers, in reality OCI images do not prevent at all other usages.
As already stated, OCI images are essentially some metadata manifest(s) and a set of layers called blobs that are essentially tar files. Images are served over an HTTP protocol. This scheme is so straightforward that client tools could be easily constructed to fetch and unpack OCI images in non container environments.
For example, the following code snippet shows a simple shell script that will fetch and unpack onto a local directory the contents of the latest AMD64 Postgres container image on Dockerhub:
#!/bin/sh
TOKEN=$( curl -s "https://auth.docker.io/token?service=registry.docker.io&scope=repository:library/postgres:pull" \
| jq -r .token )
MANIFEST_INDEX=$( curl -s -H "Authorization: Bearer $TOKEN" \
https://registry-1.docker.io/v2/library/postgres/manifests/latest )
AMD64_MANIFEST_DIGEST=$( echo $MANIFEST_INDEX \
|jq -r '.manifests[] | select(.platform.architecture == "amd64") .digest' )
AMD64_MANIFEST=$( curl -s -H "Authorization: Bearer $TOKEN" \
-H "Accept: application/vnd.oci.image.manifest.v1+json" \
https://registry-1.docker.io/v2/library/postgres/manifests/$AMD64_MANIFEST_DIGEST )
LAYERS=$( echo $AMD64_MANIFEST \
|jq -r '.layers[] | select(.mediaType == "application/vnd.oci.image.layer.v1.tar+gzip") .digest' )
tempfile=/tmp/$(date +%N)
mkdir $tempfile
cd $tempfile
for layer in $LAYERS
do
curl -s -H "Authorization: Bearer $TOKEN" --location \
https://registry-1.docker.io/v2/library/postgres/blobs/$layer \
| tar xzf -
done
echo "Image unpackaged at $tempfile"
https://gist.github.com/ahachete/8e9255bbd3834d7f3b0ad7c0cbb6069f
Actually, this principle is not new and has already been explored by projects like ORAS (OCI Registry As Storage) which allows to store anything in OCI registries and pull or push via simple command line tool.
So what lies ahead?
At OnGres we have started to create a next-generation infrastructure to build Postgres, plus hundreds of extensions, by leveraging OCI as described in this post. Soon we realized that this needs not (and should not) be applicable only to StackGres. It could be useful for: StackGres itself; for other Kubernetes operators (would be great for standardization); containers outside of Kubernetes (e.g. docker pull); and definitely and also very important for us, for any non-containerized environments too.
We want to contribute to the ongoing public discussion by bringing our experience from StackGres and knowledge about OCI. We plan to open source all of our work for anyone to use or build on top of Postgres-packaged-as-OCI for their own environments.
To get started, we will publish a follow-up post to this one discussing the metadata that has been so far considered for Postgres and extensions on OCI images, and how to leverage both standard and custom labels in the OCI’s metadata information.



